AIロボットも作れるのか?音声認識でロボットに仕事させる。
ゴール設定(ロボットと最初の会話プログラミング)
人口知能(AI)でロボットを動かすための部品が揃ったので、次はロボットの頭脳になるプログラムを作る。ロボットとの会話シナリオは、以下の単純なキーワードとし、音声コマンドとそれぞれに対応するアクションを実行することを目標とする。同じ処理を繰り返せば、会話らしいチャットボットも作れるだろうと思い、ここでは最初のコマンド4つをプログラミングしてみる。
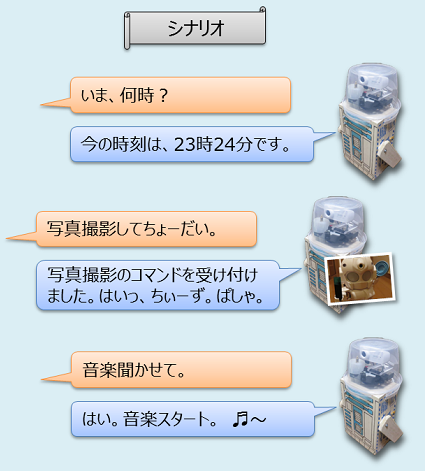
- 「いま何時?」とか「時刻を教えて」など時刻に関するキーワードを認識したら、スピーカーから「今の時刻は23時24分です」と喋ってくれる。
- 「写真」とか「撮影」とかカメラに関するキーワードなら、USBカメラで画像を取得してオンラインストレージにアップロードしてiPhoneなどモバイルで閲覧できるようにする。
- 「音楽」とか「ミュージック」などのキーワードなら、Raspberry Pi3に保存してある音楽ファイル(MP3)を再生する。
- 「終了」なら、pythonプログラムを終了する。
事前準備(フローチャート)
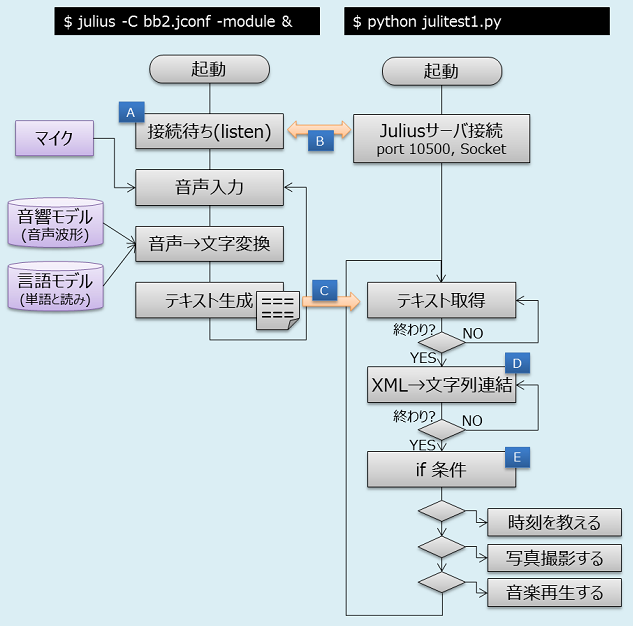
ラズパイ(Raspberry Pi3)の中で、サーバーとクライアントの両方を動かすことが複雑なので、フローチャートを用意した。Juliusサーバーを[-module]モードで起動すると、クライアント接続待ちになる[A]。pythonクライアントを起動して自分のラズパイ内のサーバー(localhost)にソケット接続する[B]。Juliusサーバーが音声入力を行うと、テキストに変換された文字列データがpythonクライアントに渡される[C]。文字列データはXMLフォーマットなので、不要なタグを無視して音声データだけを抽出する[D]。音声データを取得してしまえば、あとはひたすら[if 条件文]で登録したキーワードに対するアクションを実行する[E]。
事前準備(python クライアント プログラム)
メインループのところにある[if条件文]のキーワードを認識すると、それに対応するcmd01~cmd04までのアクションを実行します。このメインループを改造していけば、きっと人工知能みたいなロボットが作れるはず。
#!/usr/bin/python
# -*- coding: utf-8 -*-
# julitest1.py
import socket
import string
import os
import time
import datetime
import sys
import random
host = 'localhost' # Raspberry PiのIPアドレス
port = 10500 # juliusの待ち受けポート
# パソコンからTCP/IPで、自分PCのjuliusサーバに接続
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, port))
# -------------------------------
# スピーカーで喋る
# -------------------------------
def speaker( strSpeek ):
print( "[Robot] " + strSpeek )
os.system( "./jtalk.sh " + strSpeek )
# -------------------------------
# コマンド1:時刻を伝える
# -------------------------------
def cmd01_saytime():
strText = "ただいまの時刻は、" + str(datetime.datetime.today().hour) + \
"時" + str(datetime.datetime.today().minute) + "分です。"
speaker( strText )
# -------------------------------
# コマンド2:写真撮影
# -------------------------------
def cmd02_takepicture():
speaker( "写真撮影のコマンドを受け付けました。はいっ、ちぃーず。" )
# 写真撮影の実行(-D:明るさ調整、-r:サイズ、--no-banner:画像下段に日付時刻なし)
cmd = "fswebcam takepicture.jpg -D 3 -r 1280x1024 --no-banner"
os.system( cmd )
time.sleep(0.5)
speaker( "パシャ。" )
# オプション(日付と時刻を写真のファイル名に付けて、picディレクトリに保管する)
#now = datetime.datetime.now()
#cmd = "cp takepicture.jpg pic/takepic{0:%Y%m%d_%H%M%S}.jpg".format(now)
#os.system( cmd )
# オプション(AWS S3に最新画像のみアップロードして公開する)
# 事前にAWSクラウド環境の設定とラズパイにAWS CLIのインストールと設定が必要。
#cmd = "aws s3 cp takepicture.jpg s3://container-pic/takepicture.jpg"
#os.system( cmd )
# オプション(IBM Bluemix オブジェクトストレージに最新画像のみアップロードして公開する)
# 事前にIBM Bluemix (SoftLayer)クラウド環境の設定とラズパイにSwift CLIのインストール&設定が必要。
#cmd = "swift upload container-pic picture.jpg"
#os.system( cmd )
# -------------------------------
# コマンド3:音楽スタート
# -------------------------------
def cmd03_playmusic():
speaker( "はい。音楽スタート。" )
# musicディレクトリに保存されているmp3ファイル4個からランダムに選曲して再生。
# 実験なので音楽は10秒以下のものを使っています。
listMusic = ["music00.mp3", "music01.mp3", "music02.mp3", "music03.mp3"]
intTemp = random.randint(0,3)
cmd = "omxplayer music/" + listMusic[intTemp] + " -o local --vol -500 &"
os.system(cmd)
# 実験なので10秒経過したら終了する。
time.sleep(10)
speaker( "いかがでしたか?著作権フリーの音楽しか入って無いけどね。" )
# -------------------------------
# コマンド4:終了コマンド
# -------------------------------
def cmd04_exit():
strText = "終了コマンドを受け付けました。ばいばーい。"
speaker( strText )
sys.exit()
# -------------------------------
# ▽メインループ:ここから[ctrl]+[c]で終了するまで繰り返す。
# -------------------------------
try:
while True:
# 受信した音声データを入れる変数
data = ""
# "/RECOGOUT"を受信するまで、一回分の音声データを全部読み込む。
while ( string.find(data, "\n.") == -1 ):
data = data + sock.recv(1024)
# 音声(XML)データから、音声テキスト文に連結する。
strTemp = ""
for line in data.split('\n'):
index = line.find('WORD="')
if index != -1:
line = line[index+6:line.find('"',index+6)]
strTemp = strTemp + line
# デバック用:画面に音声テキスト文を表示する。
print( "[音声入力] " + strTemp )
# 音声テキストを調べて、登録したコマンドなら、アクションを実行する。
if ( string.find(strTemp, '時刻') != -1 or \
string.find(strTemp, '何時') != -1 or \
string.find(strTemp, '時間') != -1 ):
cmd01_saytime()
elif ( string.find(strTemp, '写真') != -1 or \
string.find(strTemp, 'カメラ') != -1 or \
string.find(strTemp, '撮影') != -1 ):
cmd02_takepicture()
elif ( string.find(strTemp, '音楽') != -1 or \
string.find(strTemp, 'ミュージック') != -1 ):
cmd03_playmusic()
elif ( string.find(strTemp, '終了') != -1 or \
string.find(strTemp, '終わり') != -1 ):
cmd04_exit()
# 以上、また戻る。
except KeyboardInterrupt:
print("終了")
ところで、人工知能って何だ?
[引用] 総務省の政策白書28年版に「人工知能(AI)とは」の見解として、『大まかに知的な機械、知的なコンピュータプログラムを作る科学と技術と説明されているものの、知性や知能自体の定義が無いことから、人工的な知能を定義することも困難である』としている。同白書によると、人工知能(AI)とは「人工的につくられた知能を持つ実態」とか「知的な振る舞いをするもの」「頭脳活動を極限までシミュレートするシステム」など国内の大学等研究者による定義も様々である。人工知能(AI)の歴史を見ると、1960年代の第一次人工知能ブーム(探索と推論)、冬の時代、1980年代の第二次人工知能ブーム(知識表現)、冬の時代、現在の第三次人工知能ブーム(機械学習)とあり、だいたい10年毎の周期で推移している。映画「A.I.」の放映が2001年、人工知能の表現はカラダが必須のロボットだった。同白書の「このブームをふりかえって」の説明に、社会が人工知能(AI)に期待する水準が、実現できる技術を上回ってブームが終わったと説明されており、現在のブームも一過性で終わらせないように、技術を語るのでは無くどんなことに役立っているのかを知る必要がありそうです。
まとめ(実際の動画:ロボットとの会話)
ロボットと会話ができるようになりました。音声認識が正しい言葉を認識するかどうかは、マイクの性能と周りが雑音の無い環境かどうかで認識率が違うようです。話しかける文章の中から、キーワードを見つけるだけの簡単なシナリオであれば、[if条件文]の列挙でチャットボットを作れそうです。ところで、音声認識をデモで紹介するために、下(↓)の動画を撮影しましたが、部屋でロボットに話しかけるのって、恥ずかしいというか違和感がありました。アイアンマンみたいにカッコいいアシスタントロボットに発展させたい。
