ラピロを人工知能ロボットに育てるべく、今度はチャットボット(chat bot)を組み込む。
ゴール設定(ラピロにチャットボット機能の搭載)
ラピロをペッパーやAIスピーカーに負けない人工知能ロボットに育てるべく、これまでにRECAIUSの音声認識、音声合成、多言語翻訳を搭載してきた。次はチャットボットとなるデータベースを組み込み、ラピロとたくさん会話できるようにする。

事前準備(会話データベース作成)
なんちゃってチャットだが、パターンマッチング方式でシナリオを書く
マイクロソフトのりんなや、googleのSiriみないなのを想像している。自分で書いたシナリオでは驚きがなくつまらないから、インターネットサービスのWatson Conversationとかドコモ雑談対話APIとかを試してみる。試そうと思った。Watson Conversationはトライの時点では英語のみだったのと、ドコモ雑談対話はAndroid/iOS/JavaのSDKとちょっと分かりにくかったので一旦保留、とりあえず自分でキーワードにマッチしたら適当に回答するシナリオをCSVファイルに書くことにした。Excelを使って、回答(answer)に対する質問(select)を列挙する。質問は何個あっても良いが、最初に1つでもキーワードを見つけるとその回答を優先する簡易的なものであり、例えば「犬と猫のどちらが好きですか?」と聞いても、ラピロは5行目の「わんわん。何を…略…」を喋るだけ。
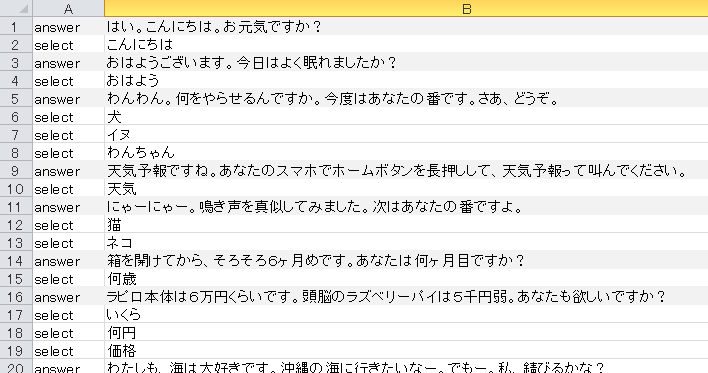
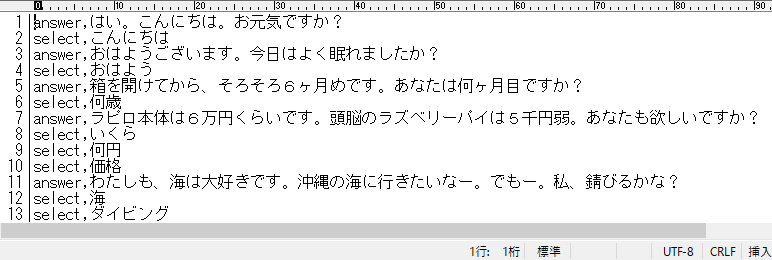
Excelで作成した会話データベースは、CSVファイル形式で保存して、pythonで読み取りし易くする。Excelが保存したCSVファイルの文字コードは[shift-jis]なので、あとでpythonで読むときに文字コード変換をしなければならない。面倒だがテキストエディタで一旦CSVファイルを読み込み、文字コード[utf-8]で再保存することで、文字コード変換しなくても済む。
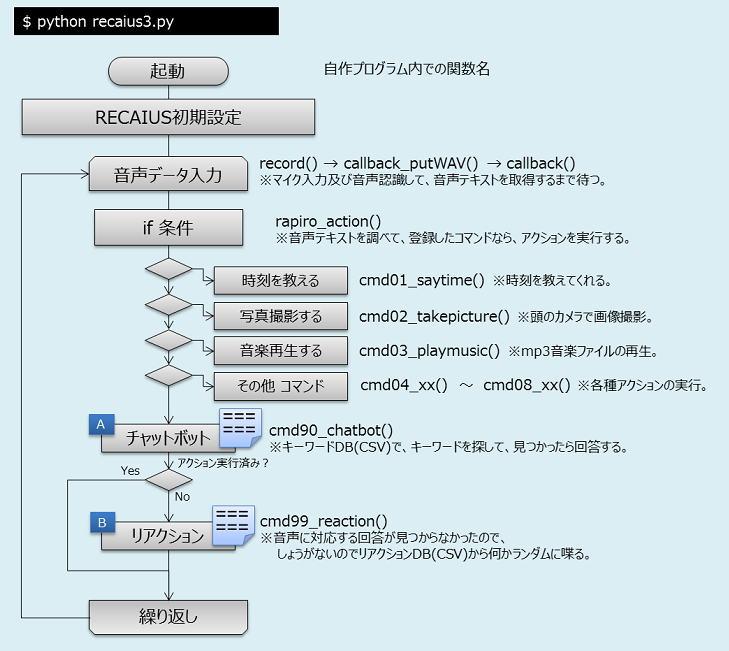
フローチャート
ラピロの動作パターンが少し高度になった。音声認識によりテキスト化した文章を3つの方式で理解する。一つ目がラピロへのコマンドであり、時計、カメラ、ミュージックプレイヤー、音量&マイク調整などである。二つ目がチャットボットであり、データベースに登録済みのキーワードに対応する文章を回答するもの([A]の部分)。三つ目は、どのパターンにも合致しなかった場合に、例えば「よく分かりません」などデタラメ回答するためのデータ集である([B]の部分)。
実験(【A】チャットボット:CSVファイルを読み込んでみる)
これが会話パターンのデータベース。CSVファイルの記述例(一部抜粋)。これをひたすら増やしていくと会話のボキャブラリーが増える。
answer,わんわん。何をやらせるんですか。今度はあなたの番です。さあ、どうぞ。 select,犬 select,イヌ select,わんちゃん answer,にゃーにゃー。鳴き声を真似してみました。次はあなたの番ですよ。 select,猫 select,ネコ
pythonスクリプトに質問文を渡して、CSVファイルを読み込んでキーワードを検索するモジュールAを作った。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# csvfile.py
import csv
import sys
import string
# -------------------------------
# コマンド90:チャットボット
# -------------------------------
def cmd90_chatbot( strText ):
# ▽キーワードDB(Excelで作ったCSVファイル)で回答を探す
csvfile = open( "chatbot.csv", "r" )
reader = csv.reader( csvfile )
for row in reader:
# print row[0]+row[1]
if ( row[0] == "answer" ):
strAnswer = row[1]
elif ( row[0] == "select" ):
strKey = row[1]
if ( string.find( strText, strKey ) != -1 ):
print( "回答=" + strAnswer )
csvfile.close()
# ===================================================
# ▼スタート
# ===================================================
if __name__ == '__main__':
if (len(sys.argv) <=1):
print("Syntax: recaius.py '質問'")
sys.exit()
else:
cmd90_chatbot( sys.argv[1] )
pythonスクリプトを実行してみる。成功。
$ python csvfile.py "犬は好きですか?" 回答=わんわん。何をやらせるんですか。今度はあなたの番です。さあ、どうぞ。
実験(【B】リアクション:CSVファイルを読み込んでみる)
リアクションのデータベース。CSVファイル例(一部抜粋)。数字はフラグで、0の場合はテキストをそのまま回答し、1の場合は元の質問と回答を連結して例えば「"あっちょんぷりけ"というのは何ですか?」と回答する
0 いいと思います。 0 うまく聞き取れないのは、僕に内蔵した安いマイクのせいなんです。 0 おっけー。明日考えるね。 1 というのは何ですか?
ランダムに文章を選んで回答するモジュールBを作った。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# reaction.py
import csv
import sys
import random
# -------------------------------
# コマンド99:しょうがないリアクション
# -------------------------------
def cmd99_reaction( strText ):
# ▽リアクションDB(Excelで作ったCSVファイル)を読み込む
listReaction = []
csvfile = open( "reaction.csv", "r" )
reader = csv.reader( csvfile )
for row in reader:
listReaction.append(row)
csvfile.close()
# ▽最大データ行数からランダムにひとつを選出
rand = random.randrange( 1, len(listReaction) )
strAnswer = listReaction[rand][0].split()
# リアクションを喋る
if ( strAnswer[0] == "1" ):
print( strText + strAnswer[1] )
else:
print( strAnswer[1] )
# ===================================================
# ▼スタート
# ===================================================
if __name__ == '__main__':
if (len(sys.argv) <=1):
print("Syntax: recaius.py '質問'")
sys.exit()
else:
cmd99_reaction( sys.argv[1] )
pythonスクリプトを実行してみる。いい感じ。
$ python reaction.py "明日は晴れますか?" 明日は晴れますか?というのは何ですか? $ python reaction.py "明日は晴れますか?" なるほどね。そういうのもいいですね。 $ python reaction.py "明日は晴れますか?" うまく聞き取れないのは、僕に内蔵した安いマイクのせいなんです。
実験(ラピロを起動する)
こちらがラピロのチャットボット全体のpythonスクリプトです。別ファイルの「rapiro.py」も参照しているので喋るときにラピロが動作します。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# recaius3.py
import json
import requests
import pyaudio
import string
import os
import commands
import sys
from collections import deque
import time
import datetime
import random
import httplib
import csv
import codecs
# 別ファイルの[rapiro.py]を参照します
import rapiro
# ===================================================
# ■定義(プログラム)
# ===================================================
glbFrames = deque()
glbToken = ""
glbUUID = ""
glbWavFile = "output.wav"
glbVoiceID = 1
glbVolume = 0 # 範囲 -50~50
glbThreshold = 300 # 範囲 0~1000
glbBlink = 0
# ===================================================
# ■定義(RECAIUS開発者サイトで取得したID,パスワード)
# ===================================================
glbRecaiusApiUrl = "https://api.recaius.jp"
glbRecaiusPassword = "自分のパスワードを書いてください"
glbRecaiusListenJP = "自分のIDを書いてください"
glbRecaiusListenEN = "自分のIDを書いてください"
glbRecaiusListenCN = "自分のIDを書いてください"
glbRecaiusTranslate = "自分のIDを書いてください"
glbRecaiusSpeech = "自分のIDを書いてください"
# -------------------------------
# 共通コマンド:スピーカーで喋る
# -------------------------------
def cmd_speaker( strSpeek ):
print( "[ラピロ] " + strSpeek )
recaius_text2wav( strSpeek, "ja_JP-F0005-U01T", "ja_JP" )
# ↓言語IDは先頭の5文字 日本語の場合は"ja_JP"
# ja_JP-F0006-C53T サクラ 日本語 女性 感情あり
# ja_JP-F0005-U01T モエ 日本語 女性 キャラクター声
# ja_JP-M0001-H00T イタル 日本語 男性 落ち着いた声
# ja_JP-M0002-H01T ヒロト 日本語 男性 若い声
# en_US-F0001-H00T ジェーン 米語 女性 落ち着いた声
# zh_CN-en_US-F0002-H00T リンリー 北京語 女性 落ち着いた声
# -------------------------------
# コマンド1:時刻を伝える
# -------------------------------
def cmd01_saytime():
rapiro.arm( "right" )
strText = "ただいまの時刻は、" + str(datetime.datetime.today().hour) + \
"時" + str(datetime.datetime.today().minute) + "分です。"
cmd_speaker( strText )
# -------------------------------
# コマンド2:写真撮影
# -------------------------------
def cmd02_takepicture():
rapiro.arm( "up" )
cmd_speaker( "写真撮影のコマンドを受け付けました。はいっ、ちぃーず。" )
# 写真撮影の実行(ファイル名、-D:明るさ調整、-r:サイズ、--no-banner:画像下段に日付時刻なし)
cmd = "fswebcam picture.jpg -D 3 -r 1280x1024 --no-banner"
os.system( cmd )
time.sleep(0.5)
rapiro.arm( "spread" )
cmd_speaker( "パシャ。" )
# オプション(日付と時刻を写真のファイル名に付けて、picディレクトリに保管する)
#now = datetime.datetime.now()
#cmd = "cp picture.jpg pic/pic{0:%Y%m%d_%H%M%S}.jpg".format(now)
#os.system( cmd )
# オプション(AWS S3に最新画像のみアップロードして公開する)
# 事前にAWSクラウド環境の設定とラズパイにAWS CLIのインストールと設定が必要。
#cmd = "aws s3 cp picture.jpg s3://container-pic/picture.jpg"
#os.system( cmd )
# オプション(IBM Bluemix オブジェクトストレージに最新画像のみアップロードして公開する)
# 事前にIBM Bluemixクラウド環境の設定とラズパイにSwift CLIのインストール&設定が必要。
#cmd = "swift upload container-pic picture.jpg"
#os.system( cmd )
# -------------------------------
# コマンド3:音楽スタート
# -------------------------------
def cmd03_playmusic():
rapiro.face( "left" )
cmd_speaker( "はい。音楽スタート。" )
# musicディレクトリに保存されているmp3ファイル4個からランダムに選曲して再生。
# 実験なので音楽は10秒以下のものを使っています。
listMusic = ["music00.mp3", "music01.mp3", "music02.mp3", "music03.mp3"]
intTemp = random.randint(0,3)
cmd = "omxplayer music/" + listMusic[intTemp] + " -o local --vol -500 &"
os.system(cmd)
# 実験なので10秒経過したら終了する。
time.sleep(10)
rapiro.arm( "right" )
cmd_speaker( "いかがでしたか?著作権フリーの音楽しか入って無いけどね。" )
# -------------------------------
# コマンド4:終了コマンド
# -------------------------------
def cmd04_exit():
rapiro.direct("#M5")
strText = "終了コマンドを受け付けました。ばいばーい。"
cmd_speaker( strText )
rapiro.reset()
sys.exit()
# -------------------------------
# コマンド5:音量変更 [範囲-50~50]
# -------------------------------
def cmd05_volume( strText ):
global glbVolume
rapiro.face("random")
if ( string.find(strText, 'アップ') != -1 or \
string.find(strText, '大') != -1 ):
if( glbVolume <= 30 ):
glbVolume = glbVolume + 20
cmd_speaker( "音量を大きくしました。" )
else:
cmd_speaker( "これ以上音量を大きくすると壊れちゃいますよ。" )
elif ( string.find(strText, 'ダウン') != -1 or \
string.find(strText, '小') != -1 ):
if( glbVolume >= -30 ):
glbVolume = glbVolume - 20
cmd_speaker( "音量を小さくしました。" )
else:
cmd_speaker( "これ以上音量を小さくすると聞こえなくなりますよ。" )
cmd_speaker( "音量は" + str(glbVolume) + "です。" )
# -------------------------------
# コマンド6:マイク感度を変更
# -------------------------------
def cmd06_threshold( strText ):
global glbThreshold
rapiro.face("random")
if ( string.find(strText, 'アップ') != -1 ):
if( glbThreshold <= 1000 ):
glbThreshold = glbThreshold + 200
cmd_speaker( "マイク感度を大きくしました。" )
else:
cmd_speaker( "これ以上変更できません。" )
elif ( string.find(strText, 'ダウン') != -1 ):
if( glbThreshold >= 200 ):
glbThreshold = glbThreshold - 100
cmd_speaker( "マイク感度を小さくしました。" )
else:
cmd_speaker( "これ以上変更できません。" )
cmd_speaker( "マイクの感度は" + str(glbThreshold) + "です。" )
# -------------------------------
# コマンド7:日本語を英語に翻訳
# -------------------------------
def cmd07_translate( strText ):
global glbVolume
strText = strText.replace( "翻訳", "" )
print( '[翻訳前] ' + strText )
strReturn = recaius_translation( strText, 'ja', 'en' )
print( '[翻訳後] ' + strReturn )
rapiro.face("left")
glbVolume = glbVolume + 20
recaius_text2wav( strReturn, "en_US-F0001-H00T", "en_US" )
glbVolume = glbVolume - 20
# 中国語への翻訳の場合
# strReturn = recaius_translation( strText, 'ja', 'zh' )
# print( '[翻訳後] ' + strReturn )
# recaius_text2wav( strReturn, "zh_CN-en_US-F0002-H00T", "zh_CN" )
# -------------------------------
# コマンド8:温度計を読んで報告
# -------------------------------
def cmd08_temperature():
rapiro.direct( "#M8" )
cmd = "cat /sys/bus/w1/devices/28-031652ddc4ff/w1_slave | "
cmd += "perl -e 'while(){if(/t=([-0-9]+)/){print $1/1000;}}'"
rtn = commands.getoutput( cmd )
print( "温度 = " + rtn + "°C" )
rtn = int(round(float(rtn),0))
strText = "ロボット内蔵の温度センサーでは、" + str(rtn) + "度です。"
cmd_speaker( strText )
# -------------------------------
# コマンド90:チャットボット
# -------------------------------
def cmd90_chatbot( strText ):
# ▽キーワードDB(Excelで作ったCSVファイル)で回答を探す
csvfile = open( "chatbot.csv", "r" )
reader = csv.reader( csvfile )
for row in reader:
if ( row[0] == "answer" ):
strAnswer = row[1]
elif ( row[0] == "select" ):
strKey = row[1]
if ( string.find( strText, strKey ) != -1 ):
# キーワードが見つかったので対応するテキストを回答する
cmd_speaker( strAnswer )
return "answered"
csvfile.close()
return "no answered"
# -------------------------------
# コマンド99:しょうがないリアクション
# -------------------------------
def cmd99_reaction( strText ):
# ▽リアクションDB(Excelで作ったCSVファイル)を読み込む
listReaction = []
csvfile = open( "reaction.csv", "r" )
reader = csv.reader( csvfile )
for row in reader:
listReaction.append(row)
csvfile.close()
# ▽最大データ行数からランダムにひとつを選出
rand = random.randrange( 1, len(listReaction) )
strAnswer = listReaction[rand][0].split()
# リアクションを喋る
if ( strAnswer[0] == "1" ):
cmd_speaker( strText + strAnswer[1] )
else:
cmd_speaker( strAnswer[1] )
# ===================================================
# ■ラピロのアクション集
# ===================================================
def rapiro_action( strText ):
rapiro.led( "green" )
print( "[音声入力]" + strText )
# 音声テキストを調べて、登録したコマンドなら、アクションを実行する。
if ( string.find(strText, '時刻') != -1 or \
string.find(strText, '何時') != -1 or \
string.find(strText, '時間') != -1 ):
cmd01_saytime()
elif ( string.find(strText, '写真') != -1 or \
string.find(strText, 'カメラ') != -1 or \
string.find(strText, '撮影') != -1 ):
cmd02_takepicture()
elif ( string.find(strText, '音楽') != -1 or \
string.find(strText, 'ミュージック') != -1 ):
cmd03_playmusic()
elif ( string.find(strText, '終了') != -1 or \
string.find(strText, '終わり') != -1 ):
cmd04_exit()
elif ( string.find(strText, 'ボリューム') != -1 or \
string.find(strText, '音量') != -1 ):
cmd05_volume( strText )
elif ( string.find(strText, 'マイク') != -1 and \
string.find(strText, '感度') != -1 ):
cmd06_threshold( strText )
elif ( string.find(strText, '翻訳') != -1 ):
cmd07_translate( strText )
elif ( string.find(strText, '温度') != -1 or \
string.find(strText, '何度') != -1 or \
string.find(strText, '気温') != -1 or \
string.find(strText, '室温') != -1 ):
cmd08_temperature()
else:
# チャットボット又はリアクションを実行する
rapiro.face( "random" )
if ( cmd90_chatbot( strText ) != "answered" ):
cmd99_reaction( strText )
rapiro.reset()
# ===================================================
# ■RECAIUS REST-APIその1(トークンの取得)
# ------------------------------------
# ユーザIDとパスワードをPOSTすると、トークンを取得でき、
# そのトークンを共通キーにして、(1)音声送信、(2)テキスト受信を行う。
# ===================================================
def recaius_gettoken( strLang ):
# 言語の取得
if ( strLang == 'JP' ):
strServiceID = glbRecaiusListenJP
strRequestBody = 'speech_recog_jaJP'
elif ( strLang == 'EN' ):
strServiceID = glbRecaiusListenEN
strRequestBody = 'speech_recog_enUS'
elif ( strLang == 'CN' ):
strServiceID = glbRecaiusListenCN
strRequestBody = 'speech_recog_zhCN'
elif ( strLang == 'Translate' ):
strServiceID = glbRecaiusTranslate
strRequestBody = 'machine_translation'
else:
print( "[ERROR] 音声認識のトークン言語を選択してください。recaiusini.py" )
sys.exit()
# HTTPリクエスト(POST)
headers = { "Content-Type": "application/json" }
body = {
strRequestBody :{
'service_id': strServiceID,
'password' : glbRecaiusPassword
},
"expiry_sec": 3600
}
# HTTPリクエスト実行
req = requests.post(
glbRecaiusApiUrl + "/auth/v2/tokens",
data = json.dumps( body ),
headers = headers
)
# HTTPリクエスト結果
if (req.status_code == 201): # 201=正常, 4xx/5xx=エラー
objJson = json.loads(req.content)
return objJson['token']
else:
print "ERROR: RECAIUS認証失敗(StatusCode=" + str(req.status_code) + ")"
sys.exit()
# ===================================================
# ■マイクの音声をWAV形式のファイルで録音する。
# ------------------------------------
# RECAIUSの仕様に合わせる(サンプル幅 16bit, サンプリング周波数 16kHz, チャンネル数 1)
# ===================================================
def record():
# PyAudioを使ってマイクから入力する音声データをどんどんcallback()関数に詰め込む
p = pyaudio.PyAudio()
stream = p.open(format = pyaudio.paInt16, # 16bit
channels = 1, # 1: モノ 2: ステレオ
rate = 16000, # 16kHzがRECAIUS音声認識用。44.1kHzは不可。32kHzは誤認識する。
input = True,
frames_per_buffer = int( 16000 * 0.512 ), # Chunk
stream_callback = callback)
stream.start_stream()
# 音声データの取得をcallback()関数内で繰り返す
while stream.is_active():
time.sleep(0.001)
# ===================================================
# ■メインループとして、音声データを取り込み、アクションを実行。
# ===================================================
def callback(in_data, frame_count, time_info, status):
global glbFrames, glbVoiceID, glbBlink
glbFrames.append(in_data)
if (len(glbFrames) > 1):
# WAVファイルをPUTして音声テキストに変換する。
strTemp = callback_putWAV()
if ( glbBlink == 0 ):
rapiro.led( "blue" )
glbBlink = 1
else:
rapiro.led( "black" )
glbBlink = 0
# 音声テキストがあればアクションする。
if ( len(strTemp) > 0 ):
objJson = json.loads(strTemp)
print( strTemp.encode('utf_8') )
for strParm,strText in objJson:
if( strParm.encode('utf_8') == 'RESULT' ):
rapiro_action( strText.encode('utf_8') )
glbVoiceID = glbVoiceID + 1
return (in_data, pyaudio.paContinue)
# ===================================================
# ■RECAIUS REST-APIその2(音声認識セッションを開始)
# ------------------------------------
# 音声認識のセッションIDに使うUUIDを取得する。
# ===================================================
def recaius_callback_getuuid():
global glbUUID
# HTTPリクエスト(POST)
headers = {
"Content-Type": "application/json",
"X-Token": glbToken
}
body = {
"model_id": 1, # 日本語(1) 英語(5) 中国語(7)
"energy_threshold": glbThreshold # 目安 170:スマートフォン ~ 400:騒音あり
}
# HTTPリクエスト実行
req = requests.post(
glbRecaiusApiUrl + "/asr/v2/voices",
data = json.dumps( body ),
headers = headers
)
# HTTPリクエスト結果
if (req.status_code == 201): # 201:成功
objJson = json.loads(req.content)
glbUUID = objJson['uuid']
print( "[RECAIUS音声認識] UUID = " + str(glbUUID) )
else:
print( "ERROR: UUID取得が失敗" + str(req.status_code) )
sys.exit()
# ===================================================
# ■RECAIUS REST-APIその3(オンライン音声認識)
# ------------------------------------
# 音声データ(wav形式)を送信し、認識結果の文字列を取得する。
# ===================================================
def callback_putWAV():
# HTTPリクエスト(PUT)
headers = {
"Content-Type": "multipart/form-data",
"X-Token": glbToken
}
body = {
'voice_id': glbVoiceID
}
files = {
'voice': (glbWavFile, glbFrames.pop(), 'application/octet-stream')
}
# HTTPリクエスト実行
req = requests.put(
glbRecaiusApiUrl + "/asr/v2/voices/" + glbUUID,
headers = headers,
data = body,
files = files
)
# HTTPリクエスト結果
return( req.text )
# ===================================================
# ■RECAIUS REST-APIその4(翻訳実行 machine_translation)
# ------------------------------------
# 日本語テキストを送信すると、英語テキストを取得できる。英→日や、日→中、中→日なども試用できた。
# ===================================================
def recaius_translation( strText, strFrom, strTo ):
strSubToken = recaius_gettoken("Translate")
# HTTPリクエスト(POST)
headers = {
"Content-Type": "application/json",
"X-Token" : strSubToken
}
body = {
"mode" : "spoken_language", # = 口語翻訳
"query" : strText,
"src_lang" : strFrom, # 試用版の選択肢: ja, en, zh
"tgt_lang" : strTo # 試用版の選択肢: ja, en, zh
}
# HTTPリクエスト実行
req = requests.post(
glbRecaiusApiUrl + "/mt/v2/translate",
data = json.dumps( body ),
headers = headers
)
# HTTPリクエスト結果
if (req.status_code == 200):
objJson = json.loads(req.content)
return str(objJson['data']['translations'][0]['translatedText'].encode('utf-8') )
else:
print( "翻訳に失敗しました。[recaius_translation() in recaius2.py]" )
return "Translation error"
# ===================================================
# ■RECAIUS REST-APIその5(話す)
# ------------------------------------
# 音声合成(To_Speech)そしてスピーチ実行!
# ===================================================
def recaius_text2wav( strText, strID, strLang ):
# HTTPリクエスト(POST) …ファイルを取得するのでhttplibモジュールを使う。
conn = httplib.HTTPSConnection( "api.recaius.jp" )
params = {
'id' : glbRecaiusSpeech,
'password' : glbRecaiusPassword,
'speaker_id' : strID,
'lang' : strLang,
'plain_text' : strText,
'codec' : 'audio/x-linear',
'volume' : glbVolume,
'pitch' : 10
}
json_params = json.dumps( params, ensure_ascii=False )
headers = { "Content-type": "application/json" }
# HTTPリクエスト実行
conn.request( "POST", "/tts/v1/plaintext2speechwave", json_params, headers)
# HTTPリクエスト結果
audio_data_path = "output.wav"
with open(audio_data_path, 'wb') as handle:
res = conn.getresponse()
handle.write( res.read() )
conn.close()
# 翻訳結果を喋る
os.system( "aplay -D hw:1,0 output.wav" )
# ===================================================
# ▼スタート
# ===================================================
if __name__ == '__main__':
glbToken = recaius_gettoken('JP') # RECAIUS音声認識トークンを取得(ユーザ認証)
recaius_callback_getuuid() # RECAIUS音声認識セッションID(=UUID)を取得
record() # RECAIUS音声認識を実行する
まとめ(ラピロにチャットボット機能を搭載した)
パターンマッチング方式でシナリオに沿った会話ならできるようになった。キーワードしか検索しないので、文脈は無視、しかもデータに存在しないときは、デタラメ回答ができるナンチャッテ人口無能だが、パターンデータを増やせばデタラメ回答になる確率も下がるはず。CSVファイルにデータを書き込むだけで、会話のボキャブラリーを増やせるので、うまいことインターネットでクローリングしてデータ拡張できれば、人工知能に近づけられるかも。次回は、ラピロを操作する音声コマンドを拡張する。

