ラピロに"IBM Watson"の音声認識を使ってみた
IBM Cloud のライトアカウントに1ヶ月あたり100分間まで無料のSpeech To Textがあったので、ラピロ(RAPIRO)で音声認識してみた。
なぜワトソンの音声認識を使うの?
音声をテキストに変換するだけならラズパイ単体で実行できるJuliusの方が応答速度が速い。でも単語辞書が弱いので文章の認識精度があまり良くなかったので他の仕組みを探してた。ワトソンだったらクラウドで動いてます~、とか Powered by Watson~とか、かっこいいかなーと思った。
無料プランの課題
ひとつ問題だったのが100分間までという時間制限。なるべく音声認識させる時間を短くするため、待機時の無音部分のデータはIBM Cloudに送信しない方が効率良いだろうと思い、音声データを取り込む際、一旦、音声データファイル(wav形式)だけを作成してからIBM Cloudに送信する手順とした。そしたら、音声データ(wav形式)を送信する時間と音声認識の回答を待つ時間が数秒かかってしまい、えらいレスポンス悪くなってしまった。次回は音声を聞き取りながら同時にデータ送信する手順を考えよっと。
手順
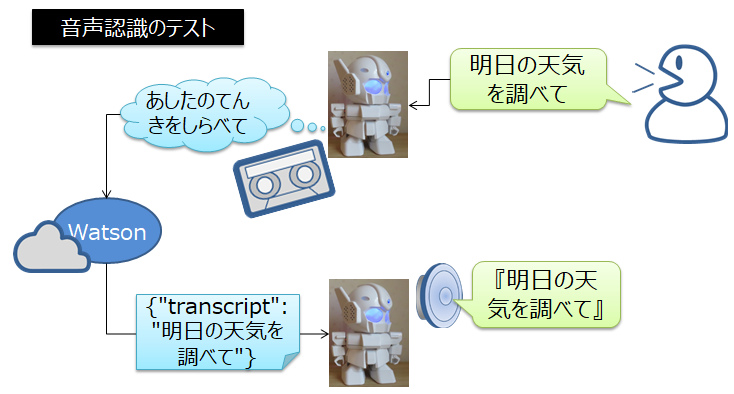
実験
スクリプト(音声を録音する)
ラピロのマイクで音声を入力して、ファイル[output.wav]に音声データを出力します。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import time
import pyaudio
import sys
import wave
import os
import codecs
CHUNK = 1024
FORMAT = pyaudio.paInt16 # 16bit
CHANNELS = 1 # mono
RATE = 16000 # 16Khz
SEND_DATA_SEC = 0.512
WAVE_OUTPUT_FILENAME = "output.wav"
frames = []
def callback(in_data, frame_count, time_info, status):
global frames
frames.append(in_data)
return (in_data, pyaudio.paContinue)
# Recording microphone voice to WAVE format file
def record():
print("### 1. ラピロが聞く準備中(PyAudioをOpen)")
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK,
stream_callback=callback)
print("### 2. ラピロが聞いています(streamingで録音)")
stream.start_stream()
# non-bloking recording
while stream.is_active():
c = input("何か一文字インプットして[Enter]キーを押すと終了します...")
if c:
break
time.sleep(0.1)
print("### 3. ラピロが聞き終えました(output.wavに保存)")
stream.stop_stream()
stream.close()
p.terminate()
# print("* ファイル[Output.wav]に音声データを保存する")
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
record()
スクリプト(IBM Watson Speech to Text 音声からテキストに変換する)
IBM Cloud に音声データ[output.wav]を送信して、戻ってきた音声テキストを保存します。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
from ibm_watson import SpeechToTextV1
from ibm_watson.websocket import RecognizeCallback, AudioSource
from ibm_watson import ApiException
from os.path import join, dirname
import json
import codecs
try:
authenticator = IAMAuthenticator('3ezjX****ここにAPIキーを入れる*****TOJk')
speech_to_text = SpeechToTextV1(
authenticator=authenticator
)
speech_to_text.set_service_url('https://gateway-tok.watsonplatform.net/speech-to-text/api')
speech_to_text.set_default_headers({'x-watson-learning-opt-out': "true"})
class MyRecognizeCallback(RecognizeCallback):
def __init__(self):
RecognizeCallback.__init__(self)
def on_data(self, data):
f= codecs.open('watson.txt', 'w', 'utf-8')
for i in range( len(data['results']) ) :
resultdata = data['results'][i]['alternatives'][0]['transcript']
f.write( resultdata + "\n" )
f.close
def on_error(self, error):
print('Error received: {}'.format(error))
def on_inactivity_timeout(self, error):
print('Inactivity timeout: {}'.format(error))
myRecognizeCallback = MyRecognizeCallback()
with open(join(dirname(__file__), '', 'output.wav'),
'rb') as audio_file:
audio_source = AudioSource(audio_file)
speech_to_text.recognize_using_websocket(
audio=audio_source,
content_type='audio/wav',
recognize_callback=myRecognizeCallback,
model='ja-JP_NarrowbandModel',
max_alternatives=1)
except ApiException as ex:
print("<失敗> エラーコード:" + str(ex.code) + ": " + ex.message)
スクリプト(Jtalkで音声合成)
テキストを読み込んで、jtalkで音声ファイルを作ってaplayでスピーカーを鳴らす。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import os
import codecs
def speech():
# 音声認識の結果テキストを取得
f = codecs.open( "watson.txt", "r", "utf-8" )
strText = f.read()
f.close()
# テキストをjtalkで音声合成する(話す)
strText = strText.replace(u" ","")
print(strText)
cmd = "./jtalk.sh " + strText
os.system( cmd )
speech()
jtalk.shスクリプト
#!/bin/bash voice=/usr/share/hts-voice/mei/mei_normal.htsvoice tempfile=`tempfile` option="-m $voice \ -s 48000 \ -p 240 \ -a 0.5 \ -u 0.0 \ -jm 1.0 \ -jf 1.0 \ -x /var/lib/mecab/dic/open-jtalk/naist-jdic \ -ow $tempfile" echo $1 | open_jtalk $option aplay -q -D hw:1,0 $tempfile
まとめ
IBM Cloud の Watson 音声認識を使って、ここの動画のように長い文章をきちんとテキスト化することができました。なお、音声合成は処理時間を短縮するため、クラウド通信をせずラズパイで処理した。音声データ[output.wav]を作ってから音声認識させてテキストを話すのでは、ロボットに声をかけてからの応答速度が遅いので、次は音声を聞き取りながらクラウドで音声合成する同時処理を考えます。目標とする『RAPIRO with Watson』と書くには未だ早いな。
