ラズパイに、人の声を理解させる。
ゴール設定(マイクに喋った文章をテキストに変換する音声認識をやってみる)
ラズパイに接続したマイク内蔵USBカメラに向かって何か喋るとテキストデータに変換してくれるという音声認識(Speech To Text)をやってみる。音声認識が出来れば、ロボットのマイクに話しかけて、スピーカーから返事を鳴らすというアシスタントロボットとの会話(チャットボット)が作れるようになる。ここでの音声認識には「Julius」というフリーソフトを試します。

事前準備(Juliusのインストール)
ラズパイに音声認識エンジン「Julius」をインストールします。Juliusの一番良いところは、無料のオープンソースであることはもちろん、インターネットに繋がらないオフライン環境でも使えることです。でも、Juliusモジュール構成がやや複雑なので、難しい壁にぶちあたってもめげずにゴールまで頑張ろう。用意するモジュールは下記3つとJuliusの設定ファイル。
・Julius本体…スタンドアロンとサーバーの複数の動作モードがあります。
・言語モデル…「単語」と「読み」の辞書です。
・音響モデル…音声波形パターンをモデル化したものです。
・Julius設定ファイル…辞書や音韻モデルのファイルを指定するテキストファイル(*.jconf)です。
そして分かりにくかったのが、「ディクテーション」というもの。「Juliusディクテーション実行キット」と「音声認識実行キット」いうものがあるのですが、これは最小限の言語モデル、音響モデル、文法などがセットになった、とりあえずJuliusだけ動かしてみたいというものです。本格的にやるには、自分オリジナルの単語辞書や文法を作ったりとか拡張できます。
Julius本体をインストール
$ # Julius本体(バージョン4.4.2, 2016/9/12版)をダウンロードする。 $ wget https://ja.osdn.net/projects/julius/downloads/66547/julius-4.4.2.tar.gz $ $ # ダウンロードしたファイルを解凍します。 $ tar xvzf julius-4.4.2.tar.gz $ # 解凍したファイルの保存先に移動してコンパイルしてインストール実行。 $ cd julius-4.4.2/ $ ./configure $ make $ sudo make install
ディクテーションと音声認識実行キットをインストール
インストールする2つのモジュールには、言語モデル、音響モデル、記述文法などのファイルが含まれています。
$ # ディクテーションをダウンロードする。 $ wget https://osdn.net/projects/julius/downloads/66544/dictation-kit-v4.4.zip $ # 音声認識実行キットをダウンロードする。 $ wget https://osdn.net/projects/julius/downloads/51159/grammar-kit-v4.1.tar.gz $ $ # 解凍ファイルを保存するディレクトリを作って、そこに移動します。 $ mkdir julius-kits $ cd julius-kits $ $ # ダウンロードしたファイルを解凍します。 $ unzip /home/pi/myProgram/julius-4.4.2/dictation-kit-v4.4.zip $ tar xvzf /home/pi/myProgram/julius-4.4.2/grammar-kit-v4.1.tar.gz
ここまでに準備したファイル構成(例)
![]() あとでJulius設定ファイルにファイルの場所を定義するので、何をどこに保存したのかをきちんとメモしてください。何も考えずにダウンロードしたファイルを解凍したら、下記のように長くて面倒なディレクトリ構成になってしまいました([myProgram]ディレクトリは、私の場合のユーザ作業ディレクトリです)。
あとでJulius設定ファイルにファイルの場所を定義するので、何をどこに保存したのかをきちんとメモしてください。何も考えずにダウンロードしたファイルを解凍したら、下記のように長くて面倒なディレクトリ構成になってしまいました([myProgram]ディレクトリは、私の場合のユーザ作業ディレクトリです)。
■ディレクトリ例 /home/pi/myProgram/ # 作業ディレクトリ(私の場合) /home/pi/myProgram/julius-4.4.2/ # Julius本体をダウンロードした場所 /home/pi/myProgram/julius-4.4.2/julius-kits/dictation-kit-v4.4 # ディクテーションの場所 /home/pi/myProgram/julius-4.4.2/julius-kits/grammar-kit-v4.1 # 音声認識実行キットの場所 /home/pi/myProgram/julius-4.4.2/julius-kits/dictation-kit-v4.4 # Juliusコマンドを実行する場所 /home/pi/myProgram/julius-4.4.2/julius-kits/dictation-kit-v4.4/model/lang_m/bccwj.60k.bingram /home/pi/myProgram/julius-4.4.2/julius-kits/dictation-kit-v4.4/model/lang_m/bccwj.60k.htkdic /home/pi/myProgram/julius-4.4.2/julius-kits/dictation-kit-v4.4/model/phone_m/jnas-tri-3k16-gid.binhmm /home/pi/myProgram/julius-4.4.2/julius-kits/dictation-kit-v4.4/model/phone_m/logicalTri-3k16-gid.bin /home/pi/myProgram/julius-4.4.2/julius-kits/dictation-kit-v4.4/main.jconf # Julius設定ファイル1 /home/pi/myProgram/julius-4.4.2/julius-kits/dictation-kit-v4.4/am-gmm.jconf # Julius設定ファイル2 /home/pi/myProgram/julius-4.4.2/julius-kits/dictation-kit-v4.4/$ julius -C main.jconf -C am-gmm.jconf -demo # 実行例
Julius設定ファイルを簡単に書きたいので、下記の様にディレクトリ名を変更しても、ちゃんと動きました。
■ディレクトリ例 /home/pi/myProgram/ # ここでPythonプログラムを実行する作業ディレクトリ(私の場合) /home/pi/myProgram/julius/kits/dictation/ # ディクテーションの場所 /home/pi/myProgram/julius/kits/dictation/model/lang_m/bccwj.60k.bingram /home/pi/myProgram/julius/kits/dictation/model/lang_m/bccwj.60k.htkdic /home/pi/myProgram/julius/kits/dictation/model/phone_m/jnas-tri-3k16-gid.binhmm /home/pi/myProgram/julius/kits/dictation/model/phone_m/logicalTri-3k16-gid.bin /home/pi/myProgram/main.jconf # Julius設定ファイル /home/pi/myProgram/$ julius -C main.jconf -nostrip # 実行例
Julius設定ファイルの編集
それぞれの設定ファイルに書かれている下記4つのファイルの場所を、インストールしたディレクトリと一致させます。
この例は、最小限のパラメータでJulius設定ファイルを書いて、作業ディレクトリ「/home/pi/myProgram/」で実行する場合です。
設定ファイルは、ファイル名「bb2.jconf」の1個にまとめています。
# bb2.jconf -d julius/kits/dictation/model/lang_m/bccwj.60k.bingram # 言語モデル -v julius/kits/dictation/model/lang_m/bccwj.60k.htkdic # 発音辞書 -h julius/kits/dictation/model/phone_m/jnas-tri-3k16-gid.binhmm # 音響モデル(HMM; Hidden Markov Model) -hlist julius/kits/dictation/model/phone_m/logicalTri-3k16-gid.bin # 音響モデル(Triphoneリスト) -n 5 # n個の検索する -output 1 # 見つかった候補のうち出力する個数 -input mic # マイクから入力 -zmeanframe -rejectshort 800 # 検出した入力が閾値以下なら無視 # 注意:文字コードをJuliusが扱うutf-8に変換するオプションですが、 # これを残すと"invalid multibyte sequence"とエラーになる場合は外して動きました。 #-charconv EUC-JP UTF-8 # 文字コードutf-8で出力
実行するコマンドは(↓)
$ julius -C bb2.jconf -nostrip
実験(マイクに話かけて、テキストデータを表示する)
正しくインストール出来たのか検査をしたいので、下記コマンドを実行する。
$ # Julius設定ファイルのあるディレクトリに移動する。 $ cd /home/pi/myProgram $ # 音声認識Juliusを実行する。 $ julius -C bb2.jconf -nostrip
Juliusが正しく起動した場合
エラー表示が無く、下記のような画面が表示され、音声入力待ちになる。
----------------------- System Information end -----------------------
Notice for feature extraction (01),
*************************************************************
* Cepstral mean normalization for real-time decoding: *
* NOTICE: The first input may not be recognized, since *
* no initial mean is available on startup. *
*************************************************************
------
### read waveform input
Stat: adin_alsa: device name from ALSADEV: "hw:0"
Stat: capture audio at 16000Hz
Stat: adin_alsa: latency set to 32 msec (chunk = 512 bytes)
Stat: "hw:0": Camera [BUFFALO BSWHD06M USB Camera] device USB Audio [USB Audio] subdevice #0
STAT: AD-in thread created
<<< please speak >>>
Julius起動時、エラーの場合
初めて実行すると下記エラーが表示されて終了してしまいました。
Error: adin_alsa: cannot open PCM device "default" (No such file or directory) failed to begin input stream
エラーの対策。
$ # ALSAで認識しているデバイス番号を確認するため「arecord -l」コマンドを実行する。下図の場合、カード番号は「0」と分かる。 $ arecord -l **** ハードウェアデバイス CAPTURE のリスト **** カード 0: Camera [BUFFALO BSWHD06M USB Camera], デバイス 0: USB Audio [USB Audio] サブデバイス: 1/1 サブデバイス #0: subdevice #0 $ # マイクのカード番号(HW番号)を環境変数に設定 $ export ALSADEV=hw:0 $ # または、サブデバイスまで指定する場合は、[export ALSADEV=hw:0,0] $ $ # snd-pcm-ossモジュールを組み込む $ sudo modprobe snd-pcm-oss
マイクに話しかけて音声認識されたテキストデータが表示される
話しかける(機械に話かけるって、なんだか恥ずかしい)。文章を話している間、リアルタイムに単語が表示されたり訂正されたり、文法通りに並べなおされたりして、最終的に「明日の天気は晴れです。」と表示してくれました。デフォルトの辞書でもちゃんと音声を認識してテキストに変換できます。
pass1_best: あした の 天気 は 晴れ です 。 pass1_best_wordseq: <s> あした+名詞 の+助詞 天気+名詞 は+助詞 晴れ+名詞 です+助動詞 </s> pass1_best_phonemeseq: silB | a sh i t a | n o | t e N k i | w a | h a r e | d e s u | silE pass1_best_score: -5193.597656 ### Recognition: 2nd pass (RL heuristic best-first) STAT: 00 _default: 9458 generated, 2069 pushed, 217 nodes popped in 214 sentence1: 明日 の 天気 は 晴れ です 。 wseq1: <s> 明日+名詞 の+助詞 天気+名詞 は+助詞 晴れ+名詞 です+助動詞 </s> phseq1: silB | a sh i t a | n o | t e N k i | w a | h a r e | d e s u | silE cmscore1: 0.572 0.082 0.135 0.798 0.695 0.095 0.831 1.000 score1: -5172.756348
ごちゃごちゃと色々表示されて何だか面倒だなーっと思ってしまいましたが、表示するだけなら[pass1_best]のレコードだけを抽出すれば良い。その他のレコードをちゃんと読むと、テキストを喋らせるための音響データ、名詞や動詞、認識が正しいかどうかの確立など、関係無いと思ったレコードも何だか凄いコトが出来そうな人工知能(AI)に活用できそうですよ。
まとめ(マイクに喋った文章をテキストに変換する音声認識をやってみた)
ラズパイと音声認識エンジン「Julius」を使って、ロボットと会話するための第一歩として、ヒトが話しかけた言葉をテキスト文章に変換することが出来るようになった。しかし、この変換は画面にテキストを表示するだけなので、Juliusエンジンが出力するこれらのデータを、自分で作成するプログラムに取り込むには、もう少し勉強が必要だ。ちなみにデフォルトの辞書には「R2D2」が無いらしく、このまま変換すると「ワルツ率」とか「ある成立」とか誤認識してしまうので、自分専用辞書も作成したい。

追伸1:自分専用辞書
自分用のオリジナル辞書を作る手順も複雑だったので、メモすることにした。
# 文字コードをEUCJPに変換して、「yomi2voca.pl」を実行して、「test.dic」を作成する、一行で実行するコマンドの例。 $ sudo iconv -f utf8 -t eucjp word.yomi | ~/julius-4.4.2/julius-kits/dictation-kit-v4.4/bin/yomi2voca.pl > ~/julius-4.4.2/julius-kits/dictation-kit-v4.4/test.dic # # 辞書に追加したい単語はword.yomiに書く(↓こんな感じ)。 # ラズパイ らずぱい # R2D2 あーるつーでぃーつー # # yomi2voca.plは、ブラウザで下記URLにアクセスして取得した。 # <https://github.com/tech-sketch/JuliusForAndroid/blob/master/julius-4.2.2/gramtools/yomi2voca/yomi2voca.pl> # # ファイルが作成されていることを確認する。 $ ls ~/julius-4.4.2/julius-kits/dictation-kit-v4.4/test.dic # # 辞書ファイルが作成されていたら、Julius設定ファイル「main.jconf」に以下を追加する。 # -w ~/julius-4.4.2/julius-kits/dictation-kit-v4.4/test.dic
追伸2:音声認識したテキストを使ってチャットボットを作るには
Juliusで音声認識させてSSHコンソール画面にテキストを表示するだけでは、プログラムを作れないので、Juliusの[-module]モードというのを利用する。1台のラズパイ上で良いので、Juliusを[-module]で起動させるとサーバーモードとしてJuliusが起動します。Juliusサーバーは、自分のラズパイの中でポート10500でクライアントからの接続を待ち続けます。そして同じラズパイで、pythonのプログラムをクライアントとして起動して、自分[localhost]のポート10500に接続することで、pythonで作ったクライアントとjuliusサーバーとで通信できるようになります。マイクで入力する音声は、Juliusサーバーが音声認識をリアルタイムに処理し、pythonクライアントプログラムが、Juliusからテキストを取得します。プログラムの実行はこんな感じ(↓)
$ # サーバーモードのJuliusをバックグランドで起動する(デバックの時は、SSHコンソールを2つ起動する方が良い)。 $ julius -C bb2.jconf -module & $ $ # pythonで自作のクライアントプログラムを起動する。 $ python julitest1.py
SSHコンソールを2つ起動した場合が分かり易いかも。こんな感じ(↓)。Juliusサーバーが、マイクから音声を入力して、音声をテキストに変換してくれます。Pythonで記述したクライアントは、Juliusサーバーからテキストデータを取得します。
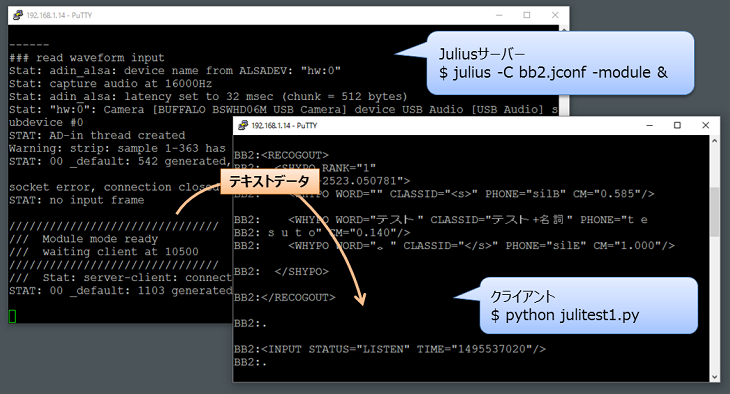
クライアント側のpythonプログラムはこんな感じで実験します(↓)。
#!/usr/bin/python
# -*- coding: utf-8 -*-
# julitest0.py
import socket
import string
host = 'localhost' # Raspberry PiのIPアドレス
port = 10500 # juliusの待ち受けポート
# パソコンからTCP/IPで、自分PCのjuliusサーバに接続
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, port))
data =""
while True:
# "/RECOGOUT"を受信するまで、一回分の音声データを全部読み込む。
while ( string.find(data, "\n.") == -1 ):
data = data + sock.recv(1024)
# 1回分の音声データを表示する。
print( data )
data = ""
クライアントが取得したテキストデータは、こんな感じのXMLデータで表示されます(↓)。読みにくいですね。WORDのデータを抽出して、自分で音声文字列データをくっつけて文章にしないといけませんね。
<INPUT STATUS="LISTEN" TIME="1495536586"/>
<INPUT STATUS="STARTREC" TIME="1495536589"/>
<STARTRECOG/>
<INPUT STATUS="ENDREC" TIME="1495536591"/>
<ENDRECOG/>
<INPUTPARAM FRAMES="223" MSEC="2230"/>
<RECOGOUT>
<SHYPO RANK="1" SCORE="-5385.860352">
<WHYPO WORD="" CLASSID="<s>" PHONE="silB" CM="0.671"/>
<WHYPO WORD="これ" CLASSID="これ+代名詞" PHONE="k o r e" CM="0.354"/>
<WHYPO WORD="は" CLASSID="は+助詞" PHONE="w a" CM="0.802"/>
<WHYPO WORD="、" CLASSID="、+補助記号" PHONE="sp" CM="0.286"/>
<WHYPO WORD="鉛筆" CLASSID="鉛筆+名詞" PHONE="e N p i ts u" CM="0.249"/>
<WHYPO WORD="です" CLASSID="です+助動詞" PHONE="d e s u" CM="0.809"/>
<WHYPO WORD="。" CLASSID="</s>" PHONE="silE" CM="1.000"/>
</SHYPO>
</RECOGOUT>
クライアント側のpythonプログラムを改造して、音声テキスト文章を取得してみます。
#!/usr/bin/python
# -*- coding: utf-8 -*-
# julitest0.py
import socket
import string
host = 'localhost' # Raspberry PiのIPアドレス
port = 10500 # juliusの待ち受けポート
# パソコンからTCP/IPで、自分PCのjuliusサーバに接続
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, port))
data =""
while True:
# "/RECOGOUT"を受信するまで、一回分の音声データを全部読み込む。
while ( string.find(data, "\n.") == -1 ):
data = data + sock.recv(1024)
# 音声XMLデータから、<WORD>を抽出して音声テキスト文に連結する。
strTemp = ""
for line in data.split('\n'):
index = line.find('WORD="')
if index != -1:
line = line[index+6:line.find('"',index+6)]
strTemp = strTemp + line
print( "結果:" + strTemp )
data = ""
今度はXMLデータ形式では無く、音声認識した文章でテキスト取得できました。クライアント側のpythonプログラムで音声をテキストで取得できるようになったので、次は、このテキストに応じたアクションをプログラミングしてみましょう。
$ python julitest0.py 結果:これは鉛筆です。 結果:五。 結果:りんごは参考。
