インターネットサービス「RECAIUS」を借りてパワーアップする(今度は英語通訳だ)
ゴール設定(ラピロを英語の通訳ロボットに改造する)
前回は、ラピロ(Rapiro)が「RECAIUS」のインターネットAPI接続を使って、音声認識してテキスト表示することが出来た。今度は、日本語から英語に翻訳して、ラピロに英語を喋ってもらう通訳ロボットになってもらうことをゴールとする。

事前準備(PythonでRECAIUSの口語翻訳APIを使う)
RECAIUSの基本的なAPI接続と音声認識
ここまででラピロが音声認識して結果をテキスト表示するプログラムが完成した。ここからは、(1)日本語テキストを英語に翻訳して、(2)英語の音声合成でラピロに英語を喋ってもらう。
音声認識プログラムの改造
RECAIUSのAPIは、サービス毎にトークンを取得するので、日本語の音声認識以外に、英語の音声認識、翻訳のそれぞれトークンが必要だったので、トークン取得の関数をマルチ言語対応にした。
前回、日本語音声のテキスト化に成功したので、ここでは翻訳と音声合成のAPI実行を追加する。改造後のフローチャートはこれ(↓)。
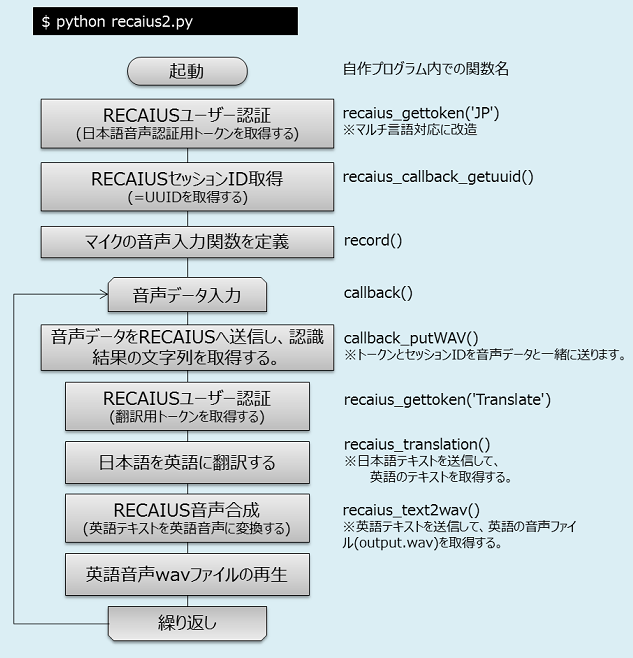
日本語を英語に通訳するPythonスクリプト
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# recaius2.py
import json
import requests
import pyaudio
import sys
from collections import deque
import time
import os
import httplib
# ===================================================
# ■定義(プログラム)
# ===================================================
glbFrames = deque()
glbToken = ""
glbUUID = ""
glbWavFile = "output.wav"
glbVoiceID = 1
# ===================================================
# ■定義(RECAIUS開発者サイトで取得したID,パスワード)
# ===================================================
glbRecaiusApiUrl = "https://api.recaius.jp"
glbRecaiusPassword = "自分のパスワードを書いてください"
glbRecaiusListenJP = "自分のIDを書いてください"
glbRecaiusListenEN = "自分のIDを書いてください"
glbRecaiusListenCN = "自分のIDを書いてください"
glbRecaiusTranslate = "自分のIDを書いてください"
glbRecaiusSpeech = "自分のIDを書いてください"
# ===================================================
# ■RECAIUS REST-APIその1(トークンの取得)
# ------------------------------------
# ユーザIDとパスワードをPOSTすると、トークンを取得でき、
# そのトークンを共通キーにして、(1)音声送信、(2)テキスト受信を行う。
# ===================================================
def recaius_gettoken( strLang ):
# 言語の取得
if ( strLang == 'JP' ):
strServiceID = glbRecaiusListenJP
strRequestBody = 'speech_recog_jaJP'
elif ( strLang == 'EN' ):
strServiceID = glbRecaiusListenEN
strRequestBody = 'speech_recog_enUS'
elif ( strLang == 'CN' ):
strServiceID = glbRecaiusListenCN
strRequestBody = 'speech_recog_zhCN'
elif ( strLang == 'Translate' ):
strServiceID = glbRecaiusTranslate
strRequestBody = 'machine_translation'
else:
print( "[ERROR] 音声認識のトークン言語を選択してください。recaiusini.py" )
sys.exit()
# HTTPリクエスト(POST)
headers = { "Content-Type": "application/json" }
body = {
strRequestBody :{
'service_id': strServiceID,
'password' : glbRecaiusPassword
},
"expiry_sec": 3600
}
# HTTPリクエスト実行
req = requests.post(
glbRecaiusApiUrl + "/auth/v2/tokens",
data = json.dumps( body ),
headers = headers
)
# HTTPリクエスト結果
if (req.status_code == 201): # 201=正常, 4xx/5xx=エラー
objJson = json.loads(req.content)
return objJson['token']
else:
print "ERROR: RECAIUS認証失敗(StatusCode=" + str(req.status_code) + ")"
sys.exit()
# ===================================================
# ■マイクの音声をWAV形式のファイルで録音する。
# ------------------------------------
# RECAIUSの仕様に合わせる(サンプル幅 16bit, サンプリング周波数 16kHz, チャンネル数 1)
# ===================================================
def record():
# PyAudioを使ってマイクから入力する音声データをどんどんcallback()関数に詰め込む
p = pyaudio.PyAudio()
stream = p.open(format = pyaudio.paInt16, # 16bit
channels = 1, # 1: モノ 2: ステレオ
rate = 16000, # 16kHzがRECAIUS音声認識用。44.1kHzは不可。32kHzは誤認識する。
input = True,
frames_per_buffer = int( 16000 * 0.512 ), # Chunk
stream_callback = callback)
stream.start_stream()
# 音声データの取得をcallback()関数内で繰り返す
while stream.is_active():
time.sleep(0.1)
# ===================================================
# ■メインループとして、音声データを取り込み、アクションを実行。
# ===================================================
def callback(in_data, frame_count, time_info, status):
global glbFrames, glbVoiceID
glbFrames.append(in_data)
if (len(glbFrames) > 1):
# WAVファイルをPUTして音声テキストに変換する。
strTemp = callback_putWAV()
# 音声テキストがあればアクションする。
if ( len(strTemp) > 0 ):
objJson = json.loads(strTemp)
strParm = objJson[0][0].encode('utf_8')
strText = objJson[0][1].encode('utf_8')
print( '[' + strParm + ']' + strText )
if (strParm == 'RESULT' ):
print( '[翻訳前]' + strText )
strReturn = recaius_translation( strText, 'ja', 'en' )
print( '[翻訳後]' + strReturn )
recaius_text2wav( strReturn, "en_US-F0001-H00T", "en_US" )
# ja_JP-F0006-C53T サクラ 日本語 女性 感情あり
# ja_JP-F0005-U01T モエ 日本語 女性 キャラクター声
# ja_JP-M0001-H00T イタル 日本語 男性 落ち着いた声
# ja_JP-M0002-H01T ヒロト 日本語 男性 若い声
# en_US-F0001-H00T ジェーン 米語 女性 落ち着いた声
# zh_CN-en_US-F0002-H00T リンリー 北京語 女性 落ち着いた声
# ko_KR-F0001-H00T ミヨン 韓国語 女性 落ち着いた声
# fr_FR-F0001-H00T ニコル 仏語 女性 落ち着いた声
glbVoiceID = glbVoiceID + 1
return (in_data, pyaudio.paContinue)
# ===================================================
# ■RECAIUS REST-APIその2(音声認識セッションを開始)
# ------------------------------------
# 音声認識のセッションIDに使うUUIDを取得する。
# ===================================================
def recaius_callback_getuuid():
global glbUUID
# HTTPリクエスト(POST)
headers = {
"Content-Type": "application/json",
"X-Token": glbToken
}
body = {
"model_id": 1, # 日本語(1) 英語(5) 中国語(7)
"energy_threshold": 400 # 目安 170:スマートフォン ~ 400:騒音あり
}
# HTTPリクエスト実行
req = requests.post(
glbRecaiusApiUrl + "/asr/v2/voices",
data = json.dumps( body ),
headers = headers
)
# HTTPリクエスト結果
if (req.status_code == 201): # 201:成功
objJson = json.loads(req.content)
glbUUID = objJson['uuid']
print( "[RECAIUS音声認識] UUID = " + str(glbUUID) )
else:
print( "ERROR: UUID取得が失敗" + str(req.status_code) )
sys.exit()
# ===================================================
# ■RECAIUS REST-APIその3(オンライン音声認識)
# ------------------------------------
# 音声データ(wav形式)を送信し、認識結果の文字列を取得する。
# ===================================================
def callback_putWAV():
# HTTPリクエスト(PUT)
headers = {
"Content-Type": "multipart/form-data",
"X-Token": glbToken
}
body = {
'voice_id': glbVoiceID
}
files = {
'voice': (glbWavFile, glbFrames.pop(), 'application/octet-stream')
}
# HTTPリクエスト実行
req = requests.put(
glbRecaiusApiUrl + "/asr/v2/voices/" + glbUUID,
headers = headers,
data = body,
files = files
)
# HTTPリクエスト結果
return( req.text )
# ===================================================
# ■RECAIUS REST-APIその4(翻訳実行 machine_translation)
# ------------------------------------
# 日本語テキストを送信すると、英語テキストを取得できる。英→日や、日→中、中→日なども試用できた。
# ===================================================
def recaius_translation( strText, strFrom, strTo ):
strSubToken = recaius_gettoken("Translate")
# HTTPリクエスト(POST)
headers = {
"Content-Type": "application/json",
"X-Token" : strSubToken
}
body = {
"mode" : "spoken_language", # = 口語翻訳
"query" : strText,
"src_lang" : strFrom, # 試用版の選択肢: ja, en, zh
"tgt_lang" : strTo # 試用版の選択肢: ja, en, zh
}
# HTTPリクエスト実行
req = requests.post(
glbRecaiusApiUrl + "/mt/v2/translate",
data = json.dumps( body ),
headers = headers
)
# HTTPリクエスト結果
if (req.status_code == 200):
objJson = json.loads(req.content)
return str(objJson['data']['translations'][0]['translatedText'].encode('utf-8') )
else:
print( "翻訳に失敗しました。[recaius_translation() in recaius2.py]" )
return "Translation error"
# ===================================================
# ■ 音声合成(To_Speech)そしてスピーチ実行!
# ===================================================
def recaius_text2wav( strText, strID, strLang ):
# HTTPリクエスト(POST) …ファイルを取得するのでhttplibモジュールを使う。
conn = httplib.HTTPSConnection( "api.recaius.jp" )
params = {
'id' : glbRecaiusSpeech,
'password' : glbRecaiusPassword,
'speaker_id' : strID,
'lang' : strLang,
'plain_text' : strText,
'codec' : 'audio/x-linear',
'volume' : 50,
'pitch' : 10
}
json_params = json.dumps( params, ensure_ascii=False )
headers = { "Content-type": "application/json" }
# HTTPリクエスト実行
conn.request( "POST", "/tts/v1/plaintext2speechwave", json_params, headers)
# HTTPリクエスト結果
audio_data_path = "output.wav"
with open(audio_data_path, 'wb') as handle:
res = conn.getresponse()
handle.write( res.read() )
conn.close()
# 翻訳結果を喋る
os.system( "aplay -D hw:1,0 output.wav" )
# ===================================================
# ▼スタート
# ===================================================
if __name__ == '__main__':
glbToken = recaius_gettoken('JP') # RECAIUS音声認識トークンを取得(ユーザ認証)
recaius_callback_getuuid() # RECAIUS音声認識セッションID(=UUID)を取得
record() # RECAIUS音声認識を実行する
実験(日英翻訳と英語を喋る)
マイクから日本語を音声入力して英語で喋ってもらう、つまり英語通訳できるロボットの実験。
[SOS] [RESULT]こんにちは。 [翻訳前]こんにちは。 [翻訳後]Good afternoon. 再生中 WAVE 'output.wav' : Signed 16 bit Little Endian, レート 22050 Hz, モノラル [SOS] [TMP_RESULT]今日は、 [TMP_RESULT]今日はとても天気が [TMP_RESULT]今日はとても天気がいいのに部屋 [TMP_RESULT]今日はとても天気がいいのに部屋にこもって [TMP_RESULT]今日はとても天気がいいのに部屋にこもってプログラムて [RESULT]今日はとても天気がいいのに、部屋にこもってプログラムをています [翻訳前]今日はとても天気がいいのに、部屋にこもってプログラムをています [翻訳後]It's a very fine day today, shut up in his room, deep in the program. 再生中 WAVE 'output.wav' : Signed 16 bit Little Endian, レート 22050 Hz, モノラル
[翻訳後]の行に注目。ちゃんと英語に翻訳されて、出力された音声ファイル(wav形式)を再生することで、ラピロのスピーカーから英語を聞くことができた。
まとめ(ラピロを英語の通訳ロボットに改造したらこうなった)
ラピロにRecaiusサービスを実装して通訳ロボットになりました。「こんにちは」って言ったら、「Hello」じゃなくて「Good Afternoon.」ってラピロが喋ってくれたことに感動した。確かに時刻は14時。まさか時刻まで加味されていないよね。日本語の発音が悪くて「プログラムをています」になっちゃったけど、それなりに訳してくれるし。しかもラピロの英語の発音はネイティブなので、これ通訳ロボットじゃなくて、英会話の先生ロボットにしちゃおうかな。いや、絶対そうすべきだ。英語の音声認識も出来るんだけど、実験してみたら、私の日本語なまりのジャングリッシュでは聞き取ってくれなかった。すんごく練習したら、ネイティブの発音できるようになるよ、きっと。そっかー、ラピロ先生の英会話教室、売れるかも。

